1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
| import requests
from bs4 import BeautifulSoup
import json
import re
import jieba
import time
USER_AGENT = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) '
'Chrome/20.0.1092.0 Safari/536.6'}
URL_TIMEOUT = 10
SLEEP_TIME = 2
# dict_result格式:{"1":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# "2":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# }
dict_result = {}
# dict_search格式:[
# [url, count]
# [url, count]
# ]
list_search_result = []
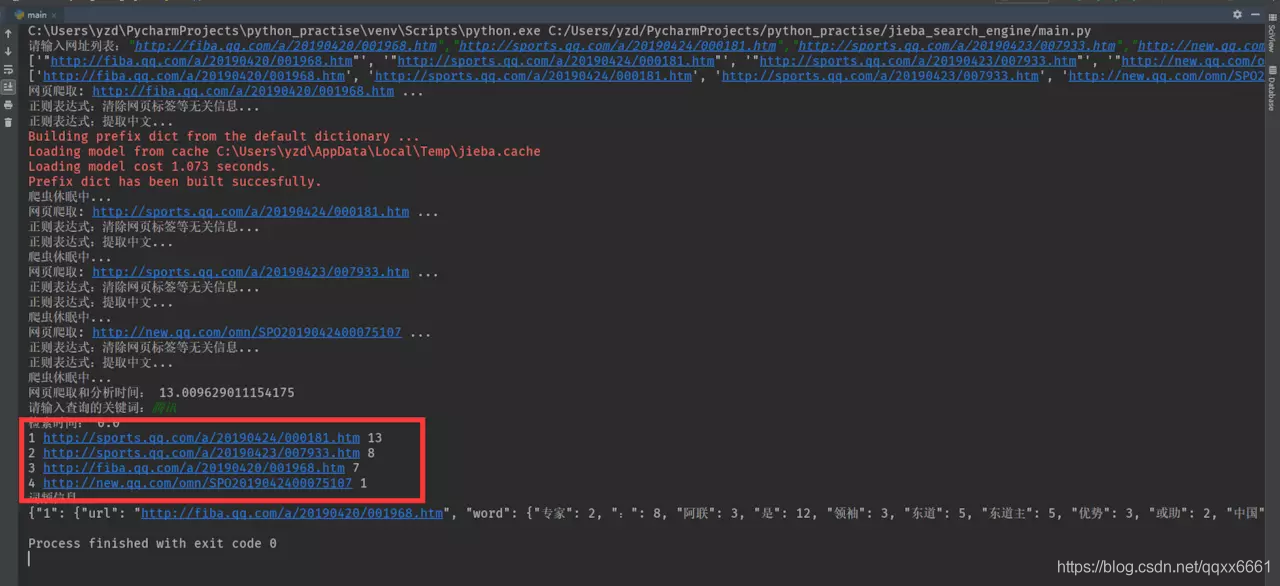
def crawler(list_URL):
for i, url in enumerate(list_URL):
print("网页爬取:", url, "...")
page = requests.get(url, headers=USER_AGENT, timeout=URL_TIMEOUT)
page.encoding = page.apparent_encoding # 防止编码解析错误
result_clean_page = bs4_page_clean(page)
result_chinese = re_chinese(result_clean_page)
# print("网页中文内容:", result_chinese)
dict_result[i + 1] = {"url": url, "word": jieba_create_index(result_chinese)}
print("爬虫休眠中...")
time.sleep(SLEEP_TIME)
def bs4_page_clean(page):
print("正则表达式:清除网页标签等无关信息...")
soup = BeautifulSoup(page.text, "html.parser")
[script.extract() for script in soup.findAll('script')]
[style.extract() for style in soup.findAll('style')]
reg1 = re.compile("<[^>]*>")
content = reg1.sub('', soup.prettify())
return str(content)
def re_chinese(content):
print("正则表达式:提取中文...")
pattern = re.compile(u'[\u1100-\uFFFD]+?')
result = pattern.findall(content)
return ''.join(result)
def jieba_create_index(string):
list_word = jieba.lcut_for_search(string)
dict_word_temp = {}
for word in list_word:
if word in dict_word_temp:
dict_word_temp[word] += 1
else:
dict_word_temp[word] = 1
return dict_word_temp
def search(string):
for k, v in dict_result.items():
if string in v["word"]:
list_search_result.append([v["url"], v["word"][string]])
# 使用词频对列表进行排序
list_search_result.sort(key=lambda x: x[1], reverse=True)
if __name__ == "__main__":
list_URL_sport = input("请输入网址列表:")
list_URL_sport = list_URL_sport.split(",")
print(list_URL_sport)
# 删除输入的网页双引号
for i in range(len(list_URL_sport)):
list_URL_sport[i] = list_URL_sport[i][1:-1]
print(list_URL_sport)
# list_URL_sport = ["http://fiba.qq.com/a/20190420/001968.htm",
# "http://sports.qq.com/a/20190424/000181.htm",
# "http://sports.qq.com/a/20190423/007933.htm",
# "http://new.qq.com/omn/SPO2019042400075107"]
time_start_crawler = time.time()
crawler(list_URL_sport)
time_end_crawler = time.time()
print("网页爬取和分析时间:", time_end_crawler - time_start_crawler)
word = input("请输入查询的关键词:")
time_start_search = time.time()
search(word)
time_end_search = time.time()
print("检索时间:", time_end_search - time_start_search)
for i, row in enumerate(list_search_result):
print(i+1, row[0], row[1])
print("词频信息:")
print(json.dumps(dict_result, ensure_ascii=False))
|